Encoding#
ASCII#
|
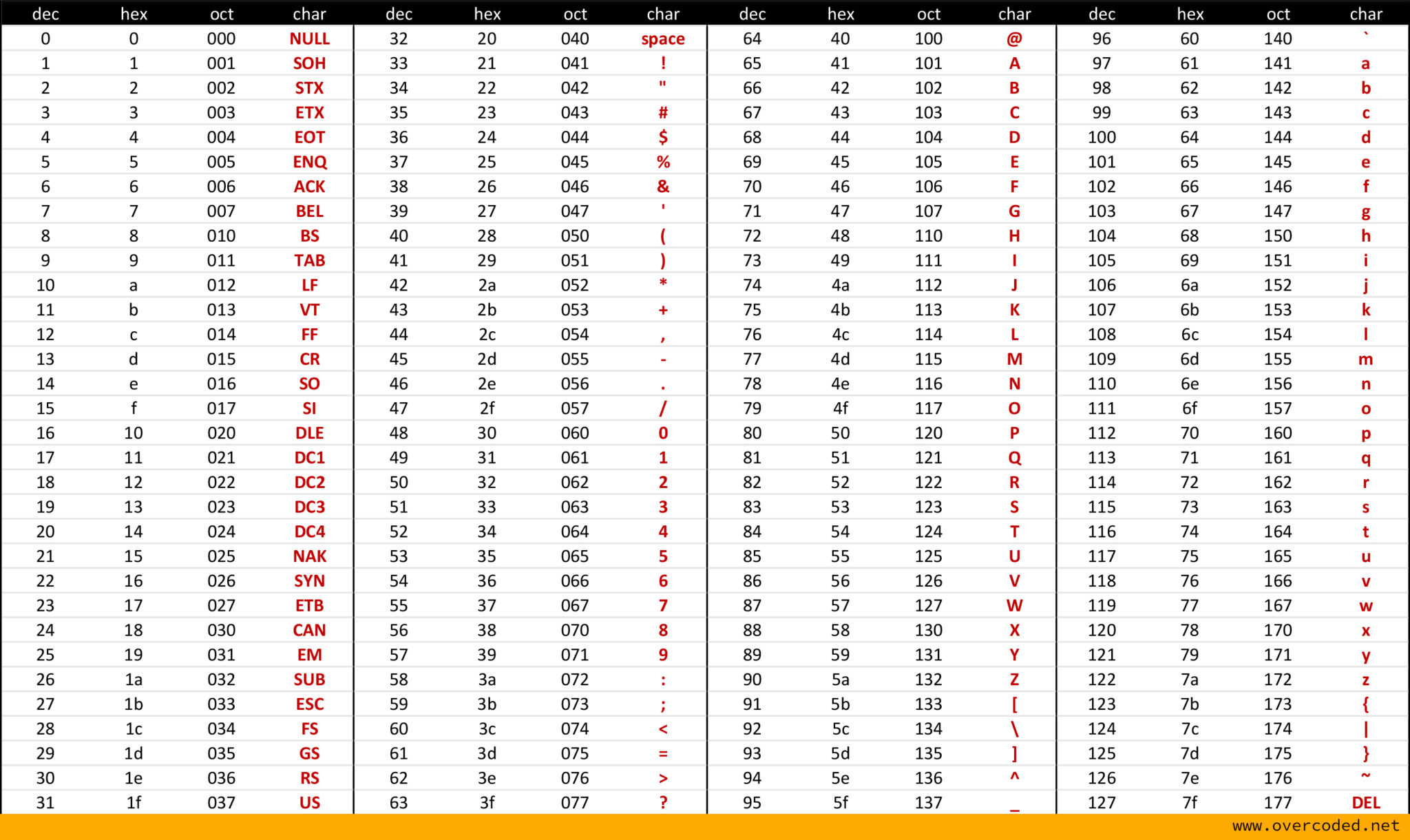
(Kindly copied from https://www.overcoded.net/ascii-table-512119/)# |
ISO Latin 1 (ISO-8859-1)#
|
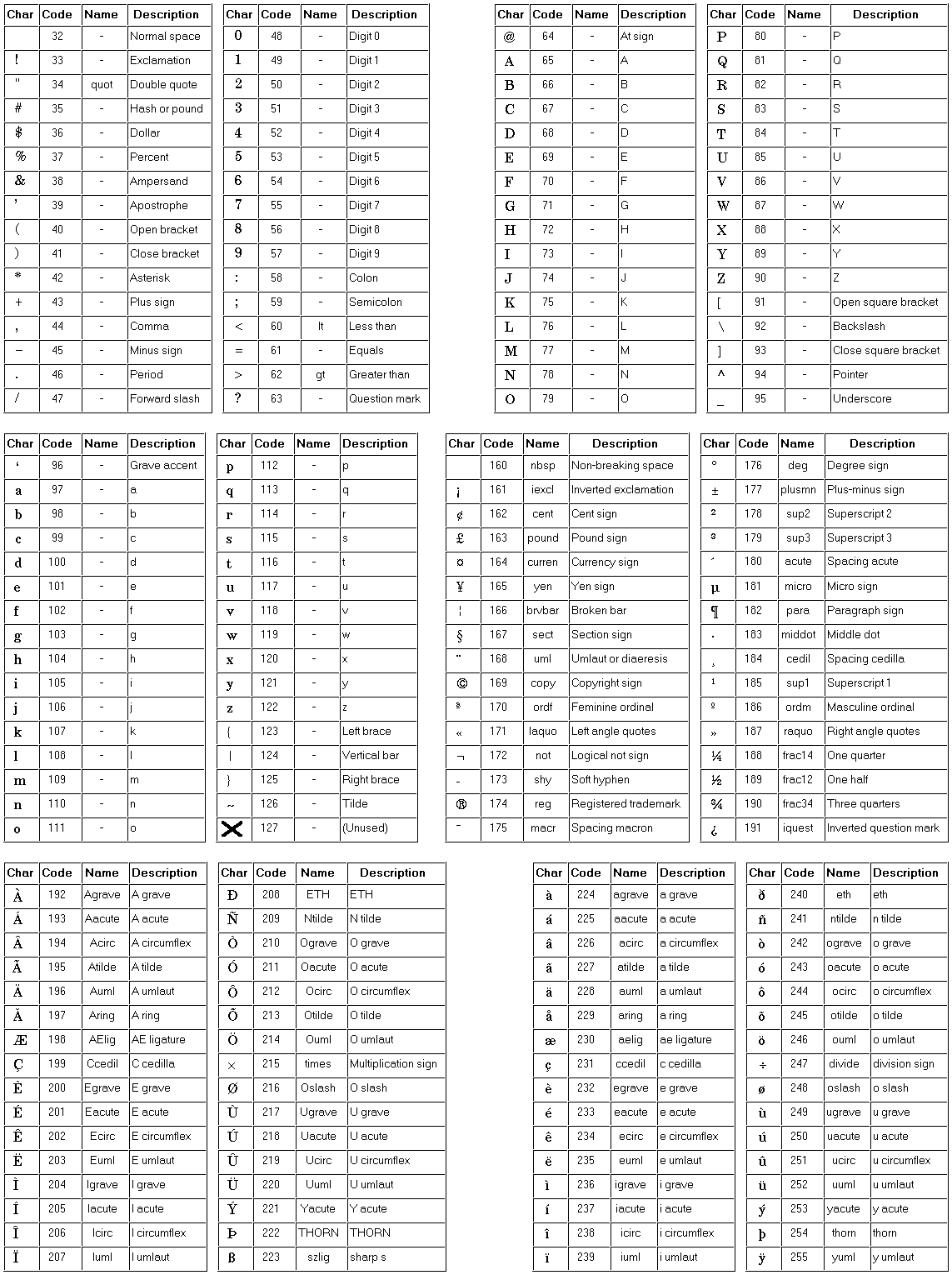
(Kindly copied from https://www.htmlhelp.com/reference/charset/latin1.gif)# |
{kind=link}
And Python?#
stris UnicodeSequence of Unicode Code Points
To differentiate the concept from characters (which are generally thought of as having eight bits)
Size of a code point is irrelevant (if at all defined)
Enough room to contain all Chinese character sets, for example
“One encoding to rule them all”
Python programs (usually) use strings internally
No encoding mistakes
Liebe Grüße, Jörg#
Python strings are Unicode ⟶ all fine (but see later) …
>>> s = 'Liebe Grüße, Jörg'
>>> type(s)
<class 'str'>
>>> len(s)
17
Is that ASCII? Probably not:
>>> s.encode(encoding='ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 8-9: ordinal not in range(128)
A Better Encoding for Liebe Grüße, Jörg: ISO-8859-1#
>>> enc = s.encode(encoding='iso-8859-1')
>>> enc
b'Liebe Gr\xfc\xdfe, J\xf6rg'
>>> type(enc)
<class 'bytes'>
>>> len(enc)
17
Bytes: 8 bit entities, not Unicode characters of transparent character size
ISO-8859-1 is a single byte encoding ⟶ 17 bytes, just as the Unicode character count in the original string.
>>> 0xfc, 0xdf, 0xf6
(252, 223, 246)
Aha. Lookup in table:
252 |
ü |
223 |
ß |
246 |
ö |
Encoding Mess#
>>> s = 'Liebe Grüße, Jörg'
>>> enc = s.encode('iso-8859-1')
Send
encin an Email (which is a chunk of bytes)Somewhere in Russia, receive Email (ISO-8859-5 is their ASCII on steroids - the Cyrillic alphabet in a single byte encoding)
>>> received_enc = enc # receive Email
>>> received_enc.decode('iso-8859-5')
'Liebe Grќпe, Jіrg'
And 祝好, Jörg? (1)#
“祝好” is Chinese for “Liebe Grüße” (kindly taken from here)
>>> lg = '祝好'
>>> len(lg)
2
|
After all, it’s two Unicode code points |
>>> lg_enc = lg.encode('big5')
>>> len(lg_enc)
4
|
|
And 祝好, Jörg? (2)#
Mixed string?
No, it’s all Unicode
>>> name = 'Jörg'
>>> bye = lg + ', ' + name
>>> bye
'祝好, Jörg'
Write that out
Need to choose an encoding
>>> bye.encode('iso-8859-1')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 0-1: ordinal not in range(256)
>>> bye.encode('big5')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'big5' codec can't encode character '\xf6' in position 5: illegal multibyte sequence
Hell!
Enter UTF-8#
Variable length encoding
Compatible with ASCII
>>> bye_enc = bye.encode('utf-8')
>>> bye_enc
b'\xe7\xa5\x9d\xe5\xa5\xbd, J\xc3\xb6rg'
A-ha: “祝好” takes 6 bytes in UTF-8
A-ha: “ö” takes 2 bytes (as opposed to one in Latin-1)
A-ha: “J”, “r”, and “g” have the same ordinal as in ASCII (not shown here)
One encoding to rule them all
Boundary Code#
Python code deals with strings internally ⟶ Unicode
Mixing Chinese with German is the norm
Technically, this is not mixing, because it is … well … Unicode
When strings leave Python at the boundary, they are converted into binary data ⟶ encoded
Explicitly, using
str.encode()Implicitly (⟶ File I/O, Web, E-Mail)
Ah Yes: decode()#
Same is true for the opposite direction: bringing bytes into a Python program, at the boundary
Explicitly, using
str.decode()Implicitly
>>> bye_enc.decode('utf-8')
'祝好, Jörg'
Of course this is not restricted to UTF-8
And Source Encoding?#
Interactive interpreter (as used in those slides)
Uses whatever encoding the terminal is set to be in
Linux is all UTF-8, nowadays
Source code
Dogmatic rule: source code is 7 bit ASCII, comments and variable names are in English
Breaking the rule leads to encoding mess
Solution (if you really want)
# -*- coding: utf-8 -*-